AI development has been all over my timeline the last weeks. ERC-4337 has always interested me from a distance but I’ve never dived in to the code or details. Seemed like a good opportunity to see how I could leverage the available tools (in this case Cursor) to build something 4337 related.
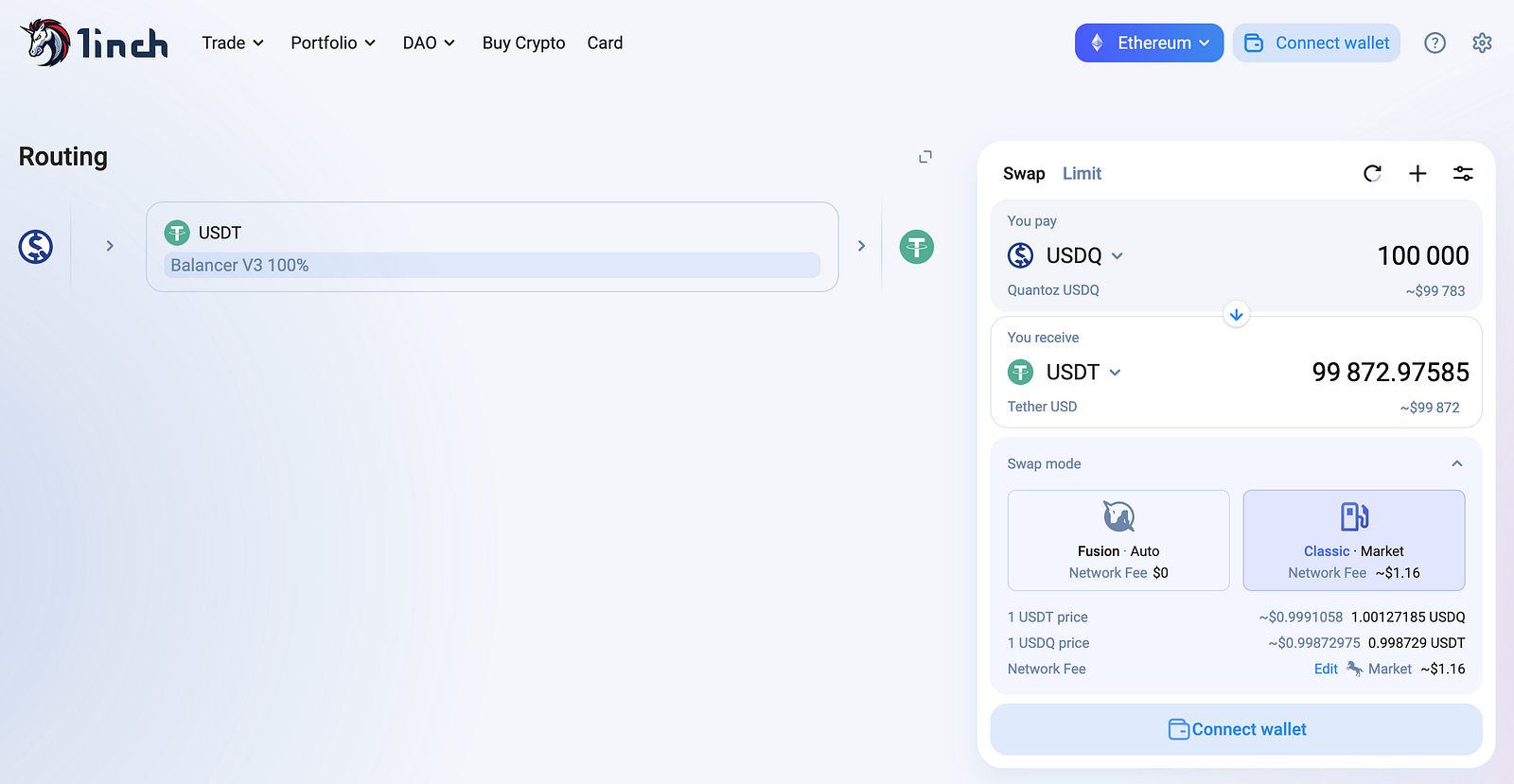
ERC-4337 Playground is a playground that lets you simulate and debug ERC-4337 UserOperations, test account deployments, transactions, and see gas breakdowns. I “vibe coded” it while reading through ERC-4337 details and here’s some of what I learned.
ERC-4337 (Quickly)
There’s so many useful resources out there that give great detail. Here’s some of the ones I found most useful:
- Awesome Account Abstraction: https://github.com/4337Mafia/awesome-account-abstraction
- What is ERC-4337? https://info.etherscan.com/what-is-erc4337/
- ERC-4337 Smart Accounts Documentation: https://docs.erc4337.io/smart-accounts/index.html
- Pimlico Documentation: https://docs.pimlico.io/
- Alchemy: User Operations Overview: https://www.alchemy.com/overviews/user-operations
- Alchemy: What is Account Abstraction? https://www.alchemy.com/overviews/what-is-account-abstraction
- Alchemy: Account Abstraction Wallet Creation: https://www.alchemy.com/blog/account-abstraction-wallet-creation
- Viem Account Abstraction: https://viem.sh/account-abstraction
At a very high level, instead of a direct transaction from an EOA, an app builds a UserOperation that gets submitted to a bundler (off-chain service), which packages and submits it to the EntryPoint contract on-chain. This enables:
- Smart contract wallets (no EOA required)
- Batch transactions
- Gas abstraction via paymasters
- Account deployment on first use
The Account
What is it?
An Account is a smart contract that acts as a user’s wallet. Its basically a smart contract that can run logic on behalf of the user. Account has at least:
- Validation logic, implementing `validateUserOp` for the EntryPoint (see below for more EntryPoint info)
- An `execute(dest, value, func)` (or equivalent) to run the UserOp’s callData
How it fits in ERC-4337?
The sender in a UserOperation is the Account’s address.
The EntryPoint only talks to the Account through a fixed validation interface. The Account must implement `validateUserOp` (and related behavior) so the EntryPoint can:
- Validate the UserOp (signature, nonce, etc.)
- Charge for gas (prefund / deposit)
- Optionally deploy the Account if it doesn’t exist yet (via initCode)
So: Account = the sender contract that implements the Account side of the ERC-4337 validation/execution interface.
How to deploy an account?
There is no global “EOA → Account” registry but there are various factory contract of Account implementation that can be used. The Account address is derived from:
- Account factory (e.g. SimpleAccountFactory)
- Owner (the EOA)
- Salt (often 0 for the “default” account)
So “EOA X has an account” means: for some (factory, owner, salt), the contract at `factory.getAddress(owner, salt)` is deployed and initialized. The address is deterministically computed, but the account only exists after deployment.
In this app we get the address by calling getAddress on the factory.
Then use:
const bytecode = await client.getBytecode({
address,
});to check if it has already been deployed. If not we give the option to deploy as part of the UserOperation (see below for a walk through).
EntryPoint
The EntryPoint is a singleton contract that validates and executes UserOperations in ERC-4337. It’s the standard’s core component and has been deployed across chains. The EntryPoint enables account abstraction by providing a standard interface for validating and executing UserOperations, without requiring changes to the Ethereum protocol.
This app uses EntryPoint v0.6, which is the current standard. Note that there are multiple EntryPoint versions (v0.6, v0.7) with different interfaces and behaviors so you should always verify which version your contracts and tooling support.
The app uses the EntryPoint to:
- Simulate UserOperations via
simulateValidation() - Fetch account nonces
- Generate UserOperation hashes for signatures
- Trace execution flows
Simulating UserOperations: Validation Without Execution
The app uses EntryPoint.simulateValidation() to validate a UserOperation without executing it. This checks signatures, nonces, deposits, and gas limits. simulateValidation() always reverts, even on success. This is because it’s designed as a view function that needs to return complex struct data. Since Solidity view functions have limitations on returning complex types, it uses a revert-with-data pattern, encoding the result in a custom error:
try {
const { result } = await client.simulateContract({
address: entryPointAddress,
abi: ENTRYPOINT_V06_ABI,
functionName: 'simulateValidation',
args: [userOp],
});
// This path is never reached - simulateValidation always reverts!
} catch (simulateError) {
// Success case: decode ValidationResult error
if (decoded?.errorName === 'ValidationResult') {
const returnInfo = decoded.args[0];
// Extract: preOpGas, prefund, sigFailed, validAfter, validUntil
return returnInfo;
}
// Failure case: decode actual error (FailedOp, etc.)
throw simulateError;
}This pattern leverages the EVM’s existing revert-with-data mechanism to return complex data. The app decodes the revert to extract validation results.
What simulation reveals
- Gas usage: actual validation gas (preOpGas) vs. the provided verificationGasLimit
- Signature status: whether signature validation passed
- Deposit requirements: how much ETH must be deposited (prefund)
- Time windows: validAfter and validUntil for time-based validation
Gas Estimation Limitations
Note: Simulated gas estimates may differ from actual on-chain execution due to state changes between simulation and execution, network conditions, bundler overhead, and other factors so you should always test with sufficient gas buffers in production.
When a paymaster is present, the app runs two simulations to separate account and paymaster validation gas:
// First: simulate without paymaster to get account-only gas
const resultWithoutPaymaster = await runSimulation(
{ ...userOp, paymasterAndData: '0x' },
entryPointAddress
);
// Second: simulate with paymaster to get total gas
const resultWithPaymaster = await runSimulation(userOp, entryPointAddress);
// Calculate: paymasterGas = totalGas - accountGasTracing Execution: Following the Call Stack
Simulation validates; tracing shows what happens during execution. The app uses debug_traceCall with EntryPoint.simulateHandleOp() to capture the full call stack.
Why simulateHandleOp?
simulateHandleOp() runs both validation and execution, so the trace includes:
- Validation phase: validateUserOp() and validatePaymasterUserOp()
- Execution phase: `Account.execute()` and downstream calls
Note: Like simulateValidation, simulateHandleOp always reverts by design—the trace data comes from analyzing the execution before the revert.
const callData = encodeFunctionData({
abi: ENTRYPOINT_V06_ABI,
functionName: 'simulateHandleOp',
args: [userOp, address(0), '0x'], // target and targetCallData allow additional calls during simulation; unused here
});
const traceResult = await client.request({
method: 'debug_traceCall',
params: [
{ to: entryPointAddress, data: callData },
'latest',
{ tracer: 'callTracer' }
],
});Building the call tree
The trace is a nested tree of contract calls. The app recursively parses it into a structured call stack:
function parseTraceFrame(frame, depth, entryPointAddress, senderAddress) {
const { name } = getFunctionName(frame.input); // Decode function selector
// Label contracts by role
let contractLabel;
if (frame.to === entryPointAddress) {
contractLabel = 'EntryPoint';
} else if (frame.to === senderAddress) {
contractLabel = 'Account';
} else if (frame.to === paymasterAddress) {
contractLabel = 'Paymaster';
}
// Recursively parse child calls
const children = frame.calls?.map(child =>
parseTraceFrame(child, depth + 1, ...)
);
return {
depth,
to: contractLabel,
functionName: name,
gasUsed: frame.gasUsed,
success: !frame.error,
children, // Nested call tree
};
}This produces a tree showing:
- EntryPoint → Account.validateUserOp()
- EntryPoint → Paymaster.validatePaymasterUserOp() (if present)
- EntryPoint → Account.execute()
- Account → External contracts (transfers, approvals, etc.)
Working together
The app runs simulation first, then tracing:
// Step 1: Simulate validation
const result = await simulateUserOp(userOp, entryPointVersion, entryPointAddress);
if (result.success) {
// Step 2: Trace execution (non-blocking)
traceUserOp(userOp, entryPointAddress, rpcUrl)
.then(trace => setTraceData(trace))
.catch(err => console.warn('Trace failed:', err));
}Why both?
- Simulation: fast validation checks, gas estimates, and error detection
- Tracing: detailed execution flow for debugging and understanding behavior
Together, they provide a complete view: whether the UserOperation will succeed and how it executes step-by-step.
Some Example Use Cases
The App highlights a couple of cool use cases for ERC-4337.
Deploying Accounts with initCode
In ERC-4337, accounts are deployed on demand using initCode. The EntryPoint checks if the account exists; if not, it uses initCode to deploy it before executing the operation.
initCode is the factory address concatenated with the encoded call to create the account:
export function encodeInitCode(factory: AccountFactory, owner: Address, salt: bigint): Hex {
const createAccountData = encodeCreateAccount(factory, owner, salt);
return concatHex([factory.address as Hex, createAccountData]);
}The factory address comes first, followed by the encoded function call (e.g., createAccount(owner, salt)). The EntryPoint calls the factory with this data to deploy the account.
In this app, we check if the account is already deployed and only include initCode if it isn’t:
// Check if account exists by checking for bytecode
const bytecode = await client.getBytecode({
address: accountSetup.computedAddress,
});
const isDeployed = !!(bytecode && bytecode !== '0x' && bytecode.length > 2);
// Only include initCode if account is not deployed
const initCode = isDeployed ? '0x' : encodeInitCode(accountSetup.factory, accountSetup.owner, accountSetup.salt);
const userOp: UserOperationV06 = {
sender: accountSetup.computedAddress,
nonce: toHex(nonce, { size: 32 }),
initCode, // Empty if deployed, contains deployment data if not
callData,
// ... other fields
};This enables account creation bundled with the first operation, reducing the number of transactions needed. The account creation still costs gas—it’s only ‘gasless’ if a paymaster covers the costs. This pattern eliminates the need for a separate deployment transaction.
How “Send 1 ETH” Works in ERC-4337
The “Send 1 ETH” button creates a UserOperation that sends 1 ETH from the smart contract account to Vitalik’s address, demonstrating ERC-4337 account abstraction.
When you click “Send 1 ETH”, the app:
1. Checks account deployment status – queries the computed address to see if the account contract exists
2. Fetches the nonce – if deployed, reads the current nonce from the EntryPoint contract:
nonce = await client.readContract({
address: ENTRYPOINT_V06,
abi: ENTRYPOINT_V06_ABI,
functionName: 'getNonce',
args: [accountSetup.computedAddress, 0n],
});3. Encodes the execution call – encodes a call to the account’s execute function:
const callData = encodeExecuteCall(
VITALIK_ETH_ADDRESS, // destination
parseEther('1'), // 1 ETH value
'0x' // empty calldata (simple ETH transfer)
);This produces calldata for execute(address dest, uint256 value, bytes func).
4. Builds the UserOperation – constructs the UserOperation with:
- sender: the account contract address
- nonce: from EntryPoint (or 0 for new accounts)
- initCode: factory deployment data if not deployed, otherwise ‘0x’
- callData: the encoded execute call
- Gas limits and fee parameters
- signature: user signature
The UserOperation is then ready for simulation via EntryPoint.simulateValidation() or submission to a bundler (an off-chain service that packages UserOperations and submits them as transactions to the EntryPoint contract on-chain).
Naughty Naughty
One of my goals was to try and develop something useful but do it quickly and in my spare time. Building a small toy/MVP gave me a bit more freedom to use work arounds that wouldn’t be recommended in prod. I thought these were fairly interesting design choices to work around friction points that normally hinder development speed or user experience.
Anvil Signer Setup: Enabling Demo Signatures For Testing
This ERC-4337 UserOperation simulator needs valid signatures to test the full flow. Since it runs in the browser without wallet connections, it uses Anvil’s default test key to generate valid signatures for demos.
Why This Was Needed
UserOperations require valid signatures. Without a wallet, the app can’t sign. Using Anvil’s well-known test key (0xac0974bec39a17e36ba4a6b4d238ff944bacb478cbed5efcae784d7bf4f2ff80) lets the app sign UserOperations when the owner matches the corresponding address (`0xf39Fd6e51aad88F6F4ce6aB8827279cffFb92266), enabling end-to-end testing without wallet integration.
⚠️ SECURITY WARNING: NEVER use Anvil’s test private key in production or with real funds. This is a well-known private key that anyone can use to sign transactions. It should only be used in local development environments or demos with test networks. Using this key with real funds will result in immediate loss.
How It Works
The app checks if the owner address matches Anvil’s test address and if the user opted in. If both are true, it generates a valid signature; otherwise, it uses an invalid placeholder to surface validation errors.
// Check if owner matches Anvil's test address
const ownerMatchesAnvil = accountSetup.owner.toLowerCase() === ANVIL_TEST_ADDRESS.toLowerCase();
const shouldGenerateValidSignature = accountSetup.useValidSignature && ownerMatchesAnvil;
let signature: Hex;
if (shouldGenerateValidSignature) {
// Generate valid signature using Anvil's private key
signature = await generateUserOpSignature(userOpWithoutSig, ENTRYPOINT_V06);
} else {
// Invalid signature to showcase validation errors
signature = `0x${'0'.repeat(130)}`;
}The signature generation uses Viem’s privateKeyToAccount to sign the UserOperation hash:
export async function generateUserOpSignature(
userOp: UserOperationV06,
entryPointAddress: Address,
chainId: bigint = 1n
): Promise<Hex> {
const account = privateKeyToAccount(ANVIL_TEST_PRIVATE_KEY);
const userOpHash = getUserOpHash(userOp, entryPointAddress, chainId);
return account.signMessage({
message: { raw: userOpHash },
});
}This approach lets users test the full ERC-4337 flow with valid signatures while keeping the app wallet-free. Users can opt in via a checkbox when using the demo owner address, or use other addresses to see validation errors.
State Override: Simulating Without Funding Accounts
State Override lets us temporarily override account state (balance, code) during RPC calls. This playground uses it so users can simulate UserOperations without funding accounts on mainnet.
Important: State overrides only work during RPC calls for simulation purposes. They have no effect on actual on-chain state and are not part of the blockchain protocol. This is purely a development/debugging feature provided by some RPC providers.
The app applies a default balance override of 100 ETH to the sender account during simulations. This is passed through Viem’s simulateContract and debug_traceCall methods.
Here’s how it’s implemented:
const { result } = await client.simulateContract({
address: entryPointAddress,
abi: ENTRYPOINT_V06_ABI,
functionName: 'simulateValidation',
args: [/* userOp params */],
stateOverride: [
{
address: userOp.sender as Address,
balance: parseEther('100'), // 100 ETH override
},
],
});Conclusion
I initially set out to see how easy it would be to vibe code an Ethereum app from scratch with the hope of learning about ERC-4337 on the way. Turns out its super productive and fun!
The planning -> implementation loop of AI assisted development really helps to learn new concepts. For best results you have to be able to instruct the agent and that means having a clear understanding of what you want to achieve and how. And being able to quickly iterate as you figure stuff out meant I was always making progress rather than getting bogged down on silly implementation issues – I felt like I spent more quality time looking at 4337 related stuff.
I’ve only just touched on ERC-4337 really, so far it seems like there’s a lot that it can do although I can definitely see some devex issues. Plenty more to dive in to!
Oh and yeah…the AI overlords are coming/here to take our jobs! Or maybe more optimistically – software development is dead, long live software development! 😅