
Intro
A big focus for Balancer Labs this year is to make it really easy to build on top of the protocol. To aid in that we’re putting together the `@balancer-labs/sdk npm package. As the current lead in this project I thought I’d try and document some of the work to help keep track of the changes, thought process and learning along the way. It’ll also be useful as a reminder of what’s going on!
SOR v2
Some background
We already have the Smart Order Router (@balancer-labs/sor), a package that devs can use to source the optimal routing for a swap using Balancer liquidity. It’s used in Balancers front-end and other projects like Copper and is a solver for Gnosis BGP. It’s also used in the Beethoven front-end (a Balancer friendly fork on Fantom, cool project and team and worth checking out).
The SOR is also used and exposed by the SDK. It’s core to making swaps accesible but is also used for joining/exiting Boosted Pools which uses PhantomBpt and swaps (a topic for another time I think!).
SOR Data
The diagram below shows some of the core parts of the SOR v2.
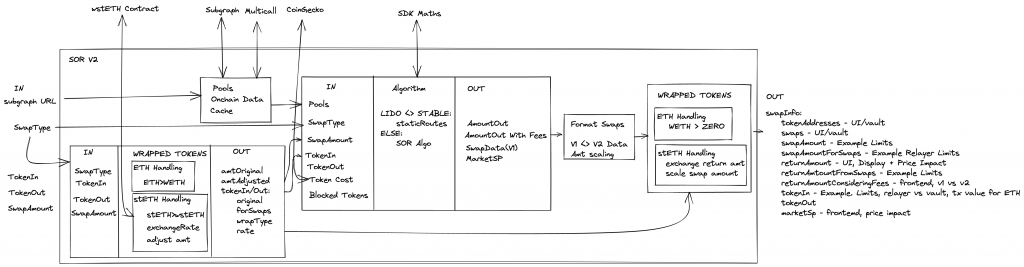
To choose the optimal routes for a swap the SOR needs information about the Balancer pools and the price of assets. And as we can see from the diagram the sourcing of this data is currently very tightly coupled to the SOR. Pools data is retrieved from the Subgraph and updated with on-chain balances using a multicall. And asset pricing is retrieved from CoinGecko.
Recently Beethoven experienced a pretty large growth spurt and found there were some major issues retrieving data from the Subgraph. They also correctly pointed out that CoinGecko doesn’t always have the asset pricing (especially on Fantom) and this information could be available from other sources.
After some discussions with Daniel (a very helpful dev from Beethoven) it was agreed that a good approach would be to refactor the SOR to create composability of data fetching so the user is able to have more control over where data is coming from. With this approach, the SOR doesn’t need to know anything about CoinGecko or the Subgraph and the data could now come from anywhere (database, cache, on chain, etc.), and as long as it implements the interface, the SOR will work properly.
Changes – SOR v3
I came back from Christmas break and Daniel had made all the changes – friendly forks for the win 💪! The interface changes are breaking but the improvements are worth it – SOR 3.0.0.
Config
The goal was to remove all the chain specific config from the SOR and pass it in as a constructor parameter. This helps to avoid non-scalable hard-coded values and encorages a single source of truth. It also gives more flexibility for the variables and makes the code easier to test.
There is now the SorConfig type:
export interface SorConfig {
chainId: number;
weth: string;
vault: string;
staBal3Pool?: { id: string; address: string };
wethStaBal3?: { id: string; address: string };
usdcConnectingPool?: { id: string; usdc: string };
}Pool Data
The goal here is to allow for flexibility in defining where the pool data is fetched from. We define a generic PoolDataService that has a single function getPools, which serves as a generic interface for fetching pool data. This allows allow for any number of custom services to be used without having to change anything in the SOR or SDK.
export interface PoolDataService {
getPools(): Promise<SubgraphPoolBase[]>;
}Approaching it this way means all the Subgraph and on-chain/multicall fetching logic is removed from the SOR. These will be added to the Balancer SDK as stand-alone services. But as a simple example this is a PoolDataService that retrieves data from Subgraph:
export class SubgraphPoolDataService implements PoolDataService {
constructor(
private readonly chainId: number,
private readonly subgraphUrl: string
) {}
public async getPools(): Promise<SubgraphPoolBase[]> {
const response = await fetch(this.subgraphUrl, {
method: 'POST',
headers: {
Accept: 'application/json',
'Content-Type': 'application/json',
},
body: JSON.stringify({ query: Query[this.chainId] }),
});
const { data } = await response.json();
return data.pools ?? [];
}
}Asset Pricing
The goal here is to allow for flexibility in defining where token prices are fetched from. We define a generic TokenPriceService that has a single function getNativeAssetPriceInToken. Similar to the PoolDataService this offers flexibility in the service that can be used, i.e. CoingeckoTokenPriceService or SubgraphTokenPriceService.
export interface TokenPriceService {
/**
* This should return the price of the native asset (ETH) in the token defined by tokenAddress.
* Example: BAL = $20 USD, ETH = $4,000 USD, then 1 ETH = 200 BAL. This function would return 200.
* @param tokenAddress
*/
getNativeAssetPriceInToken(tokenAddress: string): Promise<string>;
}All the CoinGecko code is removed from the SOR (to be added to SDK). An example TokenPriceService using CoinGecko:
export class CoingeckoTokenPriceService implements TokenPriceService {
constructor(private readonly chainId: number) {}
public async getNativeAssetPriceInToken(
tokenAddress: string
): Promise<string> {
const ethPerToken = await this.getTokenPriceInNativeAsset(tokenAddress);
// We get the price of token in terms of ETH
// We want the price of 1 ETH in terms of the token base units
return `${1 / parseFloat(ethPerToken)}`;
}
/**
* @dev Assumes that the native asset has 18 decimals
* @param tokenAddress - the address of the token contract
* @returns the price of 1 ETH in terms of the token base units
*/
async getTokenPriceInNativeAsset(tokenAddress: string): Promise<string> {
const endpoint = `https://api.coingecko.com/api/v3/simple/token_price/${this.platformId}?contract_addresses=${tokenAddress}&vs_currencies=${this.nativeAssetId}`;
const response = await fetch(endpoint, {
headers: {
Accept: 'application/json',
'Content-Type': 'application/json',
},
});
const data = await response.json();
if (
data[tokenAddress.toLowerCase()][this.nativeAssetId] === undefined
) {
throw Error('No price returned from Coingecko');
}
return data[tokenAddress.toLowerCase()][this.nativeAssetId];
}
private get platformId(): string {
switch (this.chainId) {
case 1:
return 'ethereum';
case 42:
return 'ethereum';
case 137:
return 'polygon-pos';
case 42161:
return 'arbitrum-one';
}
return '2';
}
private get nativeAssetId(): string {
switch (this.chainId) {
case 1:
return 'eth';
case 42:
return 'eth';
case 137:
return '';
case 42161:
return 'eth';
}
return '';
}
}Final Outcome
After the changes the updated diagram shows how the SOR is more focused and less opinionated:
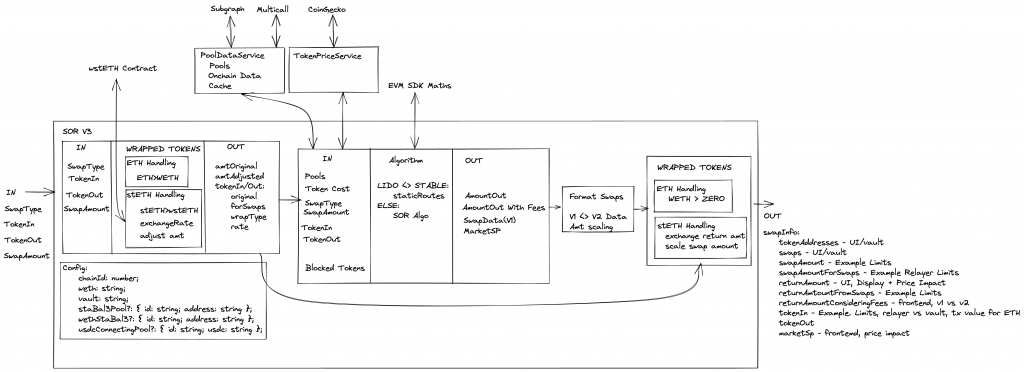
The plan for the Balancer front-end is to move away from using the SOR directly and use it via the SDK package. The SDK will have the data fetching functionality as serparate services (which can be used independetly for fetching pools, etc) and these will be passed to the SOR when the SDK is instantiated. BUT it’s also possible to use the SOR independendtly as shown in this swapExample.
This was a large and breaking change but with the continued issues with Subgraph and more teams using the SOR/SDK it was a neccessary upgrade. Many thanks to Daniel from the Beethoven team for pushing this through!